How it Works: Spam Recognition!Death2Spam is based on a "cutting edge" word-frequency distribution analyzer, which very rapidly compares the pattern of words detected in an incoming email message against a huge database of good and spam emails. The D2S classifier is an Adaptive Expert System, which is able to accurately assign each email a probability score representing the likelihood that it's spam. And it learns from its mistakes. A probability score of 100 means the email is absolutely pure, 100%, unadulterated junk. A probability of zero means it's as good as it gets. If there are too few clues in the message (very rare), or if it contains an equal number of good and spam words, the probability score will hover somewhere around 50, in a twilight zone where the classifier declares itself to be "unsure". |
|
|
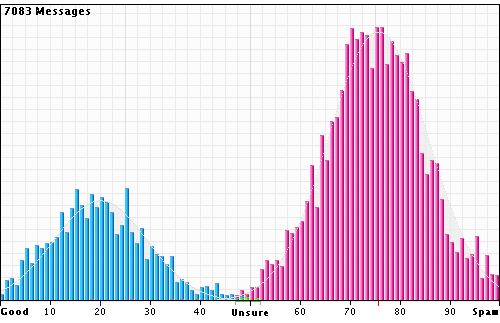
In the above graph, you see an example of the D2S spam-recognition logic hard at work, depicting many thousands of email messages being processed for a user through one of our Mail Filtering servers. In the background, you'll notice the double-humped bimodal distribution as predicted by the pseudo-Bayesian probability mathematics used in the classifier.
For the statistically minded, the "unsure" probability limits are set at ~3 standard deviations from the means of the (normalized) spam/good binomial distributions. Therefore, theoretically, the unsure zone should contain ~1% of the total number of messages. This new breed of "uncertainty logic" thereby achieves the 99% confidence level for a binary language classifier. After considerable real-world testing, the unsure zone's boundaries have been fine-tuned to reduce false positive classifications to extremely low levels (almost unmeasurable!), while keeping the total number of uncertain classifications to a realistic minimum. The D2S system is able to dynamically learn where these limits should be placed, thereby achieving its #1 design objective of 99.9% classification accuracy. Links for more information:
|